JavaScript is the language of the internet for a reason. It is used by 98% of websites as a client-side programming language making it the undisputed choice for UI and UX design. While the basic structure of a website can be created in HTML and CSS, it’s JavaScript (or its variation) that adds interactivity and logic to web pages. As websites are getting more interactive and there is a significant amount of JavaScript content on web pages, JavaScript SEO is becoming impossible to ignore. An essential part of the process is JavaScript rendering.

What is JavaScript rendering?
To optimize the JavaScript code to benefit search rankings, you must understand how this programming language is rendered in the browser.
In a webpage, JavaScript is used along with HTML and CSS to change the values and properties of an HTML tag with user-driven events such as a click of a button or choice of an option from a drop-down list. Such functionality makes a webpage dynamic. But the issue arises with content within JavaScript that we want search engines to crawl and index. Embedding content within the JavaScript to be rendered when an event is triggered hides content from search engine bots. It can cause serious JavaScript rendering issues.
How do search engines render JavaScript?
To better understand JavaScript rendering in the context of SEO, we have to know how search engines process JavaScript.
Google, the leader in the search industry, processes JavaScript web apps in three phases:
- Crawling
- Rendering
- Indexing
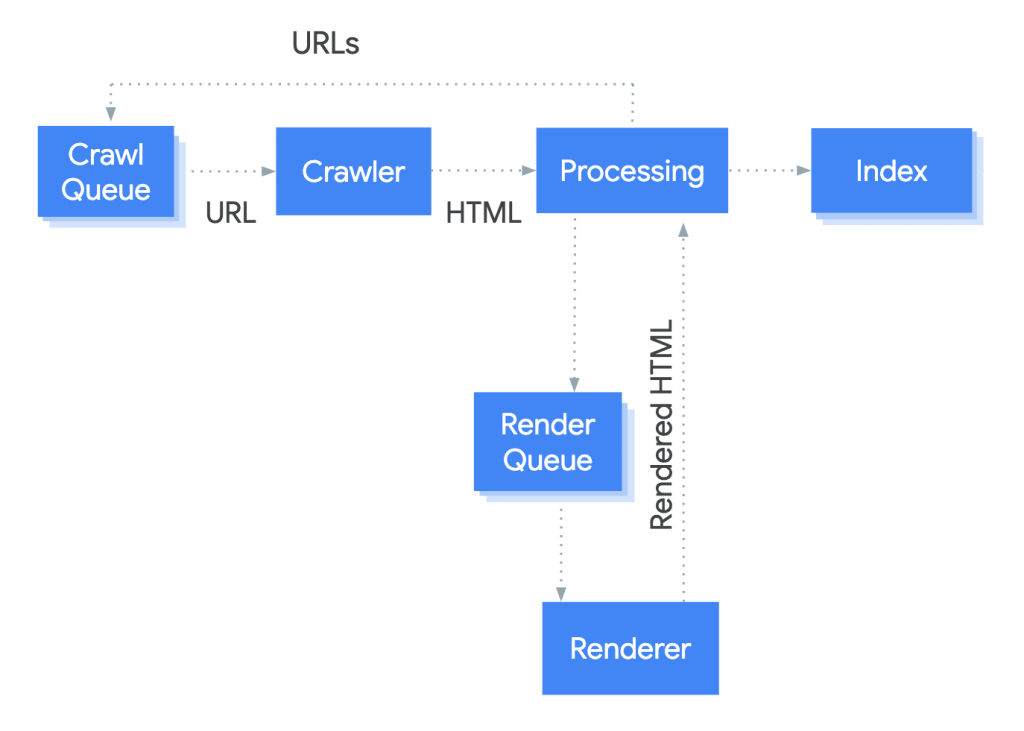
Googlebot queues for the web pages for rendering and crawling. The bot first checks for crawling permissions in the robots.txt file. If the URL is allowed to crawl, Googlebot adds it to the crawling queue.
In a standard scenario, crawling the URL and parsing the HTML response works well for classical websites that use only HTML and CSS. Such webpages are easily rendered, and search engine bots can read and index the content on these pages. However, some websites use the JavaScript app shell model where the initial HTML code does not contain the content. Search engines need to execute the JavaScript code before they can see the page that JavaScript generates.
When Google encounters such pages, it adds them to the queue for JavaScript rendering. Depending on the code’s complexity and the content’s length, it can take a few seconds before the code is rendered, so it is readable to the search engine. Once processing, a headless chromium renders the page and executes the JavaScript. Google bot parses the HTML code generated to index the page.
However, browser rendering of JavaScript is not a good idea because as results in slow web pages for both the users and crawlers. It is why Google recommends server-side or prerendering because it makes your website faster for both. Also, it helps because not all bots can run JavaScript.
How do social media platforms render JavaScript?
Social media platforms like Facebook and Twitter are not as robust as search engines when it comes to indexing content. It is important to know that most social media platforms cannot render JavaScript.
Both Facebook and Twitter’s crawlers cannot render JavaScript, so you must not include JavaScript code to feed into the open graph tags. These are the HTML tags that social media platforms use to generate cards whenever you share a link for a web page. Here’s an example:
How can you improve JavaScript rendering SEO?
We understand that your website can’t exist or function as you want to without JavaScript components. You don’t have to eliminate JavaScript content from your web pages to optimize their presence in the search engine results.
You can do plenty of things to facilitate JavaScript rendering by search engine bots.
Here are some of the best JavaScript rendering SEO techniques to use.
Avoid ‘OnClick’ links
When a web page contains ‘onclick=” window.location=”‘ links, they are not treated as ordinary links by the search engine bots. In most cases, such links will be skipped entirely as they won’t be counted as part of the navigation or as internal link signals. This can result in poor indexing of your website and affect organic ranking.
Therefore, you must keep all the links in the DOM before the click is made. It is an easy-to-implement JavaScript rendering SEO technique that can make your website easy to crawl and index. Ensure all the essential links are loaded by default without additional user action.
Avoid # in URLs
Googlebot does not support the # fragment identifier in the URL structure. This is why you must stick to clean URL formatting.
Unsupported format: example.com/#url Supported format: example.com/url
It is a common practice in JavaScript rendering to use # fragment URLs for loading different sections or pages. However, it results in poor SEO performance and must be avoided.
Unique content must have unique URLs
A common use of JavaScript rendering in a website is to change the page’s content dynamically without changing the UR. Developers might not be aware of the fact that for unique content to be indexed by the search engine, it has to be located “somewhere.”
Simply put, if you are dynamically changing the web page’s content without changing the URL, you are essentially preventing the search engine bots from accessing the unique content. If the page URL remains the same, bots will not crawl it again when dynamically new content is generated.
Avoid JS errors
If you have any development experience, you might know that HTML is very forgiving, but JavaScript is not.
If there is a single error in JavaScript code, it will simply not execute, which may cause an error in the content displayed on the web page. Furthermore, one error in the script can cause a domino effect resulting in other JS scripts is to fail. You must always keep track of JavaScript errors and fix them as soon as they occur. Google Chrome DevTools comes with tools to help you discover any JavaScript errors in your web pages.
Don’t block JS in robots.txt
JavaScript rendering SEO is not only about the webpages but also robots.txt file. Ensure that you are not blocking JavaScript files today as it was once practiced. Even some content management systems, by default, block the rendering and crawling of JavaScript files. However, it is considered a very bad practice, and even Google has said:
“We recommend making sure Googlebot can access any embedded resource that meaningfully contributes to your site’s visible content or its layout…”
Ensure that there is no JavaScript blocking code in the robots.txt file like this:
User-agent: * Disallow: /CSS Disallow: /js
If you are blocking the resources, the JavaScript SEO score might drop, bringing down the overall ranking of the web pages.
Prerender JavaScript
If crawler bots are facing issues with rendering the JavaScript files on your website, you can use prerendering to make it easier for search engine bots to discover the content.
The rendering simply provides ready-made JavaScript render HTML documents to the crawler bots. Bots receive pure HTML and not JavaScript render HTML, so they index the content much more efficiently. Also, prerendering does not affect user experience as they access the same JavaScript version of the web pages.
Several external prerendering services like Prerender.io can be used to generate a prerendered version of webpages.
Ready to discover JavaScript rendering issues?
While the above-listed JavaScript rendering SEO tips will help you fix the issue, you must discover problems first.
You can use Ranklogs Site Auditor to automatically discover JavaScript errors on every web page of your website. Our Site Auditor will not only identify the errors and potential issues but will also provide recommendations on how to tackle the discovered JavaScript rendering issues.

Conclusion
Rendering JavaScript is essential for creating dynamic websites, but it creates several challenges for SEO. We hope this JavaScript rendering SEO guide will help you investigate any issues that might affect organic traffic and the ranking of your website and fix it quickly.



Comments